k均值、合并聚类和DBSCAN聚类算法对鸢尾花数据集聚类代码.zip
”数据集 聚类 机器学习“ 的搜索结果
Model1_iris鸢尾花数据集聚类探索
鸢尾花IRIS数据集-聚类分析机器学习

二维人工数据集:6个 数据 xxx.txt 标签 xxx_cl.txt UCI真实数据集:10个 数据 xxx.txt 标签 xxx_label.txt

本次实验是一场聚类算法的深度探索之旅,涵盖了K-means、K-medoids、DBSCAN和凝聚聚类等引人注目的算法。K-means通过巧妙的迭代将样本点划分到K个簇,并通过聚类中心的不断更新优化结果。尽管简单高效,但对初始...

聚类分析也称聚类,它与分类是不同的,分类的目标变量是已知的,每个样本都存在类标签,而聚类的目标变量是事先不知道的,聚类的样本类别没有被预先定义出来。聚类是根据聚类算法或样本对象划分成两个以上的子集,每...


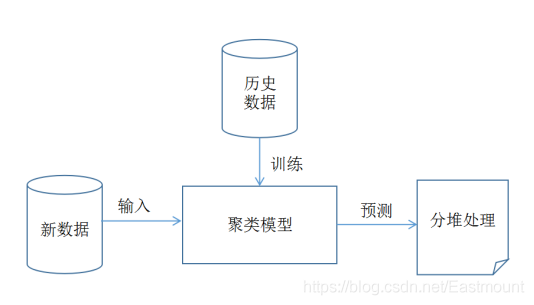
一.分散性聚类(kmeans)算法流程:1.选择聚类的个数k.2.任意产生k个聚类,然后确定聚类中心,或者直接生成k个中心。3.对每个点确定其聚类中心点。4.再计算其聚类新中心。5.重复以上步骤直到满足收敛要求。...
1、导入数据#导入花萼数据from sklearn.datasets import load_irisiris=load_iris()iris.data前四列为花萼长度,花萼宽度,花瓣长度,花瓣宽度等4个用于识别鸢尾花的属性2、建模#创建kmeans聚类from sklearn.cluster...

聚类是一种无监督的学习方法,广泛用于识别固有的数据结构,并应用于各种领域,例如数据挖掘,模式识别,机器学习等。 本文提出了一种新的拓扑聚类方法,称为δ-开放集聚类。 此方法的关键思想是确定数据中的δ-开放...
西安工程大学电子信息学院,2022级研究生研究方向:智能信息处理与信息系统研究电子邮件:[email protected]陈梦丹,女,西安工程大学电子信息学院,2022级硕士研究生,张宏伟人工智能课题组研究方向:机器视觉与...
我们需要为我们的IDLE安装sklearn库,scikit-learn是Python的一个开源机器学习模块,它建立在NumPy,SciPy和matplotlib模块之上能够为用户提供各种机器学习算法接口,可以让用户简单、高效地进行数据挖掘和数据分析...

对于云层数据集,由于数据集图像较为干净,故使用二分类即可较好的将云层分离出来
国际权威的学术组织the IEEE International Conference on Data Mining (ICDM) 2006 (香港召开)年12月评选出了数据挖掘领域的十大经典算法。不仅仅是选中的十大算法,其实参加评选的18种算法,实际上随便拿出一种来...

是scikit-learn库中的一个类,用于标签编码。它将一组文本或分类标签转换为从0。出现的标签自动构建编码映射关系。转换操作将原始标签转换为对应的编码值。方法同时执行了拟合和转换操作。如果你只需要进行转换,...
鸢尾花数据集1. 鸢尾花Iris数据集介绍2. Sklearn代码获取Iris2. 描述性统计3. 数据分布情况 1. 鸢尾花Iris数据集介绍 Iris flower数据集是1936年由Sir Ronald Fisher引入的经典多维数据集,可以作为判别分析...

数据挖掘中 异常值检测与处理

机器学习:计算机进行数据处理,找到数据间映射关系的过程 1、督学习:本数据集中的数据,包括样本数据以及样本数据的标签。通过学习找到样本数据与数据标签之间的映射关系。主要解决回归问题和分类问题。 回归...
因为本人在学习这块内容之后,发现网络上大部分现有代码的不简洁以及运行报错,再者想要的表达方法的不同,所以自己动手结合网络上已有的代码改写了一个,运行正常。
鸢尾花数据集是一组常用的机器学习数据集,其中包含150个样本,每个样本有4个特征:萼片长度、萼片宽度、花瓣长度、花瓣宽度。每个样本还有一个类别标签,分为3类:山鸢尾、变色鸢尾、维吉尼亚鸢尾。 在聚类分析中,...
推荐文章
- Python Django 版本对应表以及Mysql对应版本_django版本和mysql对应关系-程序员宅基地
- Maven的pom.xml文件结构之基本配置packaging和多模块聚合结构_pom <packaging>-程序员宅基地
- Composer 原理(二) -- 小丑_composer repositories-程序员宅基地
- W5500+F4官网TCPClient代码出现IP读取有问题,乱码问题_w5500 ping 网络助手 乱码 send(sock_tcps,tcp_server_buff,-程序员宅基地
- Python 攻克移动开发失败!_beeware-程序员宅基地
- Swift4.0_Timer 的基本使用_swift timer 暂停-程序员宅基地
- 元素三大等待-程序员宅基地
- Java软件工程师职位分析_java岗位分析-程序员宅基地
- Java:Unreachable code的解决方法_java unreachable code-程序员宅基地
- 标签data-*自定义属性值和根据data属性值查找对应标签_如何根据data-*属性获取对应的标签对象-程序员宅基地